关于我们
本平台是“嵌入知识组织体系的规模化领域预训练基础模型构建”的课题成果,课题编号:2022YFF0711901。该课题隶属于国家重点研发计划“科技文献内容深度挖掘及智能分析关键技术和软件”,项目编号:2022YFF0711900,平台网址:https://sciaiminer.las.ac.cn/。

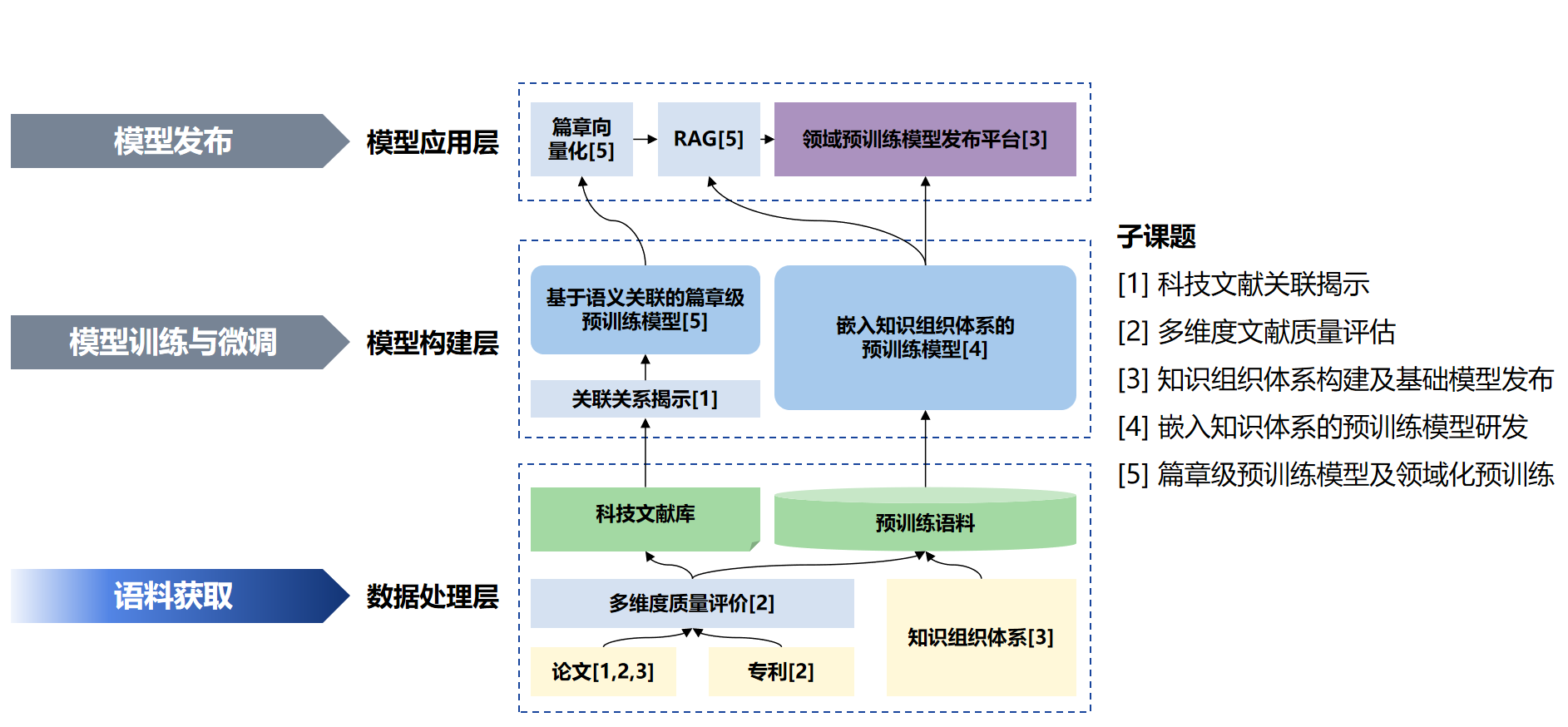
本课题面向8个重点学科领域,预期构建8个以上的领域预训练基础模型,提升科技文献内容挖掘的起跑线。课题依托于海量科技文献优势数据,研究科技文献元数据的语义标注和语义关联揭示,多维度文献质量评价体系构建,以及多粒度知识体系内容描述,系统性汇聚涵盖8个领域的优质文献,打造具有丰富语义、高质量的大规模预训练语料库。
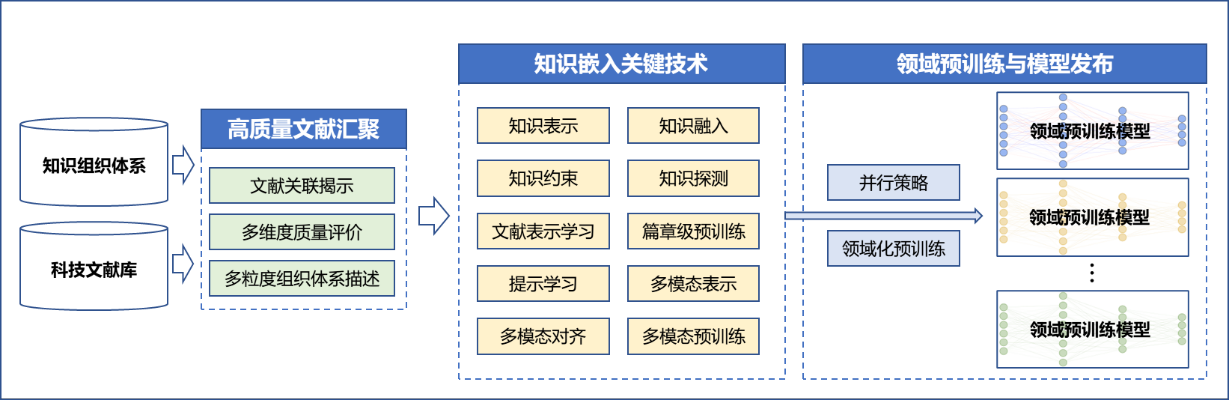
在此基础上,课题聚焦嵌入知识组织体系的预训练模型关键技术研究,充分挖掘科技文献及知识组织体系的结构与语义特征,开展知识嵌入与知识探测方法、面向科技文献典型特征的篇章级预训练模型等核心技术研究。通过调度高性能算力,采用并行化大规模训练策略,持续推动领域预训练基础模型的研发和发布,切实支撑领域科技文献内容的深入挖掘与高效利用,为AI赋能科学研究提供坚实的数据与模型底座。